
Introduction to Large Language Models (LLMs)
A Large Language Model (LLM) is an artificial intelligence (AI) system trained on vast amounts of text data to understand, generate, and manipulate human language. These models use deep learning techniques particularly neural networks to process words, sentences, and entire documents. Unlike traditional rule-based AI, LLMs learn patterns from data, allowing them to perform tasks like answering questions, writing summaries, translating languages, and even coding.
Key characteristics of LLMs:
- Massive scale: Trained on terabytes of text (books, articles, code, etc.).
- Transformer architecture: Uses a neural network design optimized for language tasks.
- General-purpose: Can adapt to various applications without task-specific programming.

Evolution of LLMs (From Early AI to Modern Transformers)
LLMs are the result of decades of progress in AI and natural language processing (NLP):
- Early AI (1950s–1990s)
- Rule-based systems (e.g., ELIZA in 1966) relied on hand-coded responses, lacking true language understanding.
- Statistical models (e.g., Hidden Markov Models) improved text prediction but were limited in complexity.
- Machine Learning Era (2000s–2010s)
- Algorithms like Word2Vec (2013) enabled word embeddings numeric representations of word meanings.
- Recurrent Neural Networks (RNNs) and LSTMs improved sequence modelling but struggled with long-range context.
- Transformer Revolution (2017–Present)
- Google’s Transformer architecture (2017) introduced self-attention, allowing models to weigh word relationships efficiently.
- This breakthrough enabled training on larger datasets, leading to modern LLMs like GPT and BERT.
Key Milestones in Large Language Models (LLMs)
| Year | Model | Developer | Significance |
|---|---|---|---|
| 2017 | Transformer | Introduced self-attention, the foundation for modern LLMs | |
| 2018 | BERT | Bidirectional training for better context understanding; improved search & NLP | |
| 2018 | GPT-1 | OpenAI | First generative pre-trained transformer (117M parameters) |
| 2019 | GPT-2 | OpenAI | Scaled to 1.5B parameters; demonstrated few-shot learning |
| 2020 | GPT-3 | OpenAI | 175B parameters; versatile text generation with minimal fine-tuning |
| 2020 | T5 | Unified text-to-text framework (translation, summarization, etc.) | |
| 2022 | ChatGPT | OpenAI | Fine-tuned GPT-3.5 for conversational AI |
| 2023-2025 | GPT-4 | OpenAI | Multimodal (text + images); improved accuracy and reasoning |
| 2023-2025 | LLaMA | Meta | Open-source model (7B–65B parameters) for research |
| 2023-2025 | Falcon | TII UAE | Open-source, commercially usable LLM (40B parameters) |
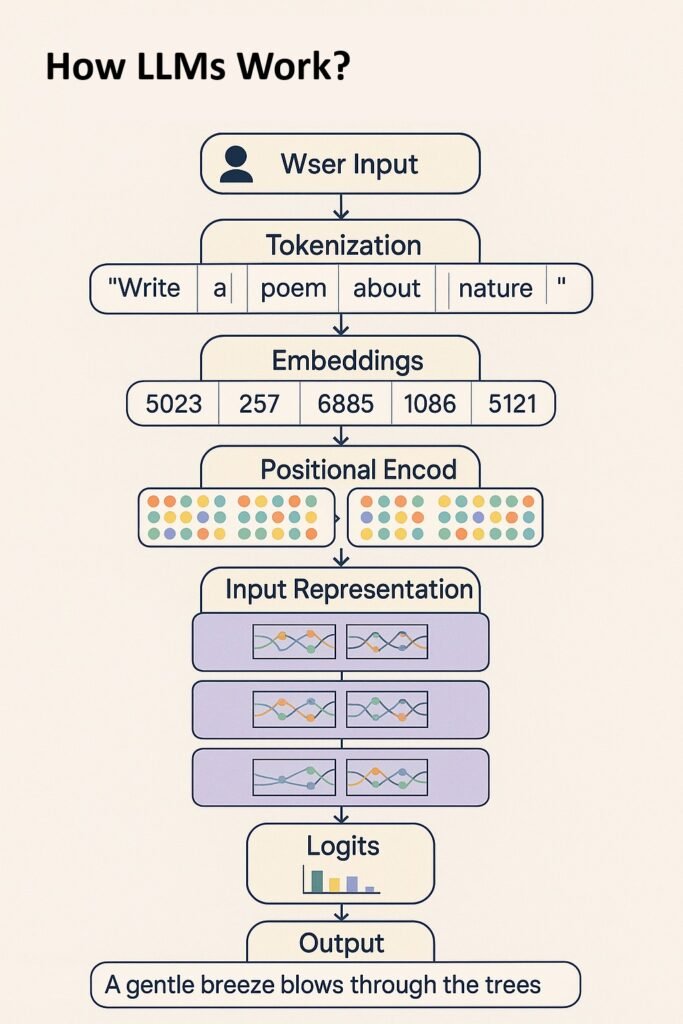
How LLMs Work?
Large Language Models (LLMs) process and generate human-like text through a sophisticated but systematic approach. Here’s how they function:
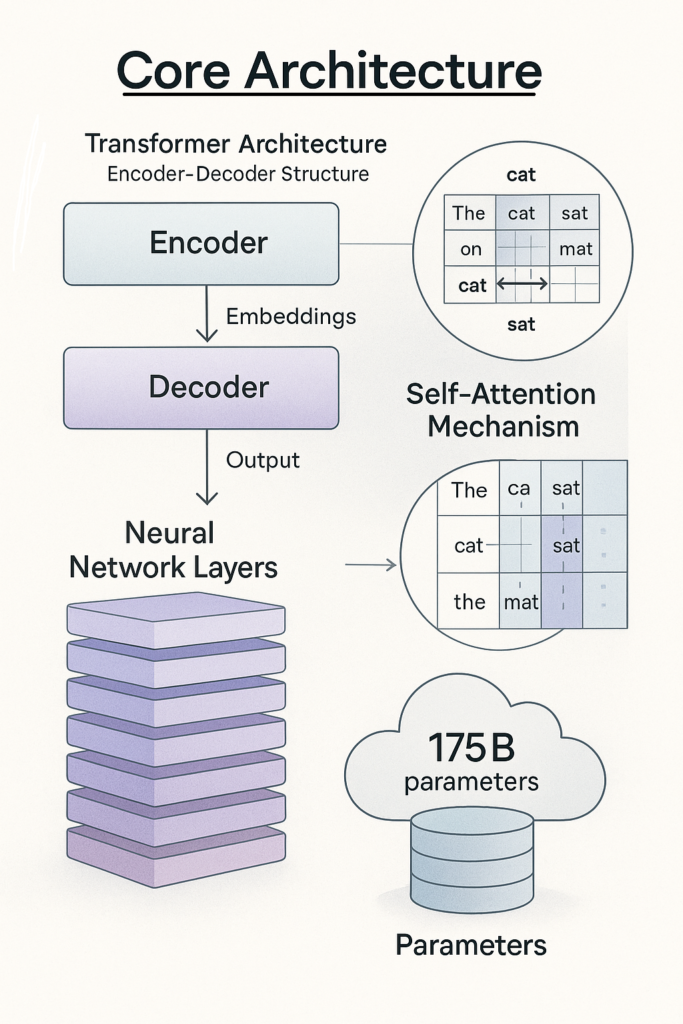
Core Architecture
LLMs are built on transformer architecture, a neural network design optimized for processing language. The key components:
- Encoder-Decoder Structure
- The encoder processes input text and creates numerical representations (embeddings).
- The decoder generates output (e.g., translations, answers) based on these embeddings.
- Self-Attention Mechanisms
- Allows the model to weigh the importance of each word in a sentence relative to others.
- Example: In “The cat sat on the mat,” it links “cat” to “sat” and “mat” to understand context.
- Neural Network Layers
- LLMs stack multiple layers (often 12–100+) to process data hierarchically.
- Each layer refines the understanding of text, from simple word meanings to complex relationships.
- Parameters
- These are the learned weights (values) in the neural network.
- Larger models (e.g., GPT-3’s 175B parameters) capture more nuanced language patterns.
With Example:
Training Process
LLMs learn in two main phases:
- Pre-training (Unsupervised Learning)
- The model analyzes massive datasets (e.g., Common Crawl, Wikipedia) to predict missing words or sentences.
- No human labels are needed it learns patterns from raw text.
- Fine-tuning (Supervised Learning)
- The pre-trained model is adjusted for specific tasks (e.g., customer support, coding) using smaller, labelled datasets.
- Example: ChatGPT was fine-tuned on human-written dialogues to improve conversation quality.
Datasets Used:
- Common Crawl (web pages), BooksCorpus, GitHub (code), and domain-specific texts.

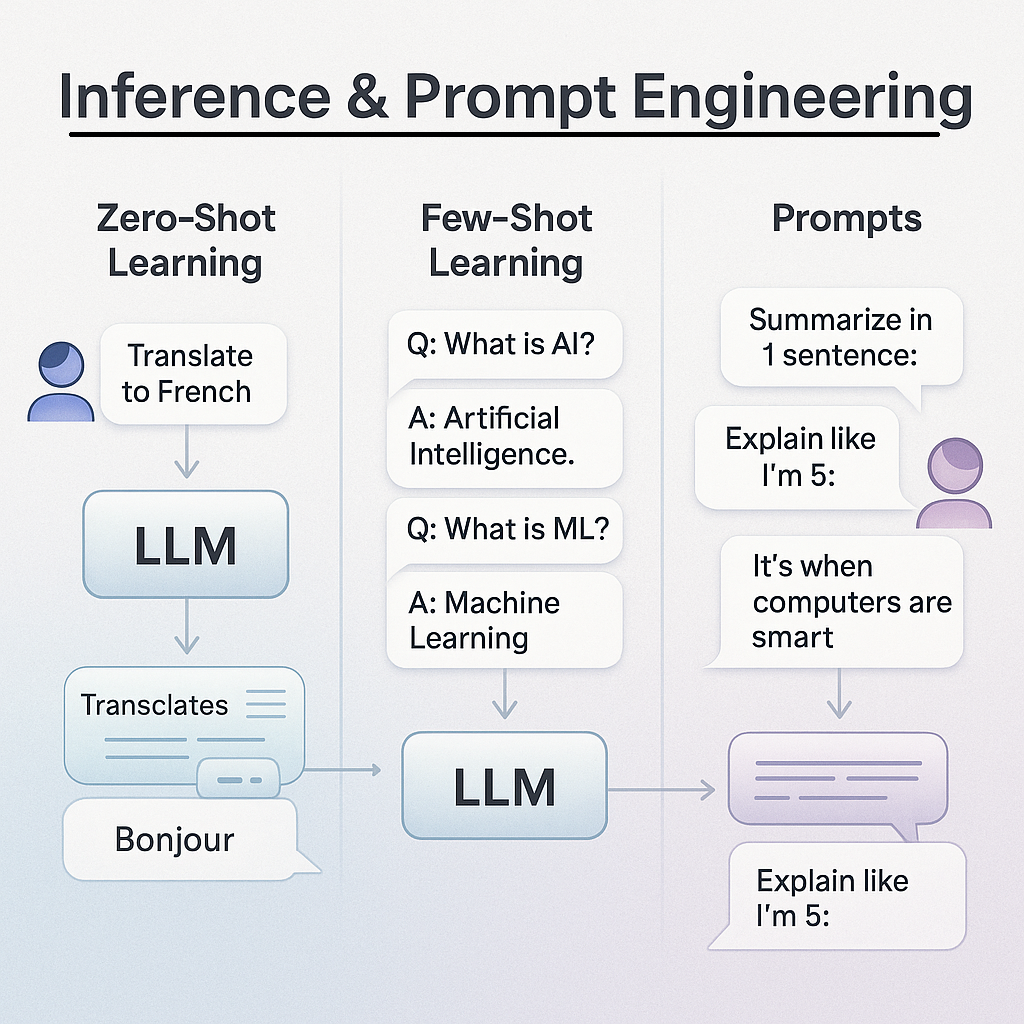
Inference & Prompt Engineering
Once trained, LLMs generate responses through:
- Zero-Shot Learning
- The model answers unseen tasks without examples (e.g., “Translate this to French”).
- Few-Shot Learning
- Providing 1–5 examples improves accuracy (e.g., “Q: What is AI? A: Artificial Intelligence. Q: What is ML?”).
- Prompts
- Input instructions that guide outputs (e.g., “Summarize in 1 sentence:” vs. “Explain like I’m 5:”).
- Clear prompts reduce errors (hallucinations) and align responses with user intent.
Applications of LLMs
Large Language Models are being used across industries to automate and enhance various tasks. Here are the key applications:
Content Generation
- Writing assistance (emails, reports, articles)
- Marketing copy creation (ads, product descriptions)
- Creative writing (stories, poetry, scripts)
Customer Support
- AI chatbots for 24/7 customer service
- Automated email responses
- FAQ generation and answering
Software Development
- Code generation and autocompletion
- Debugging assistance
- Documentation writing
- Code translation between programming languages
Business Operations
- Contract analysis and summarization
- Meeting note generation
- Data extraction from documents
- Report writing and analysis
Education & Research
- Tutoring systems
- Research paper summarization
- Language learning tools
- Plagiarism detection
Healthcare
- Medical documentation
- Literature reviews
- Patient Q&A systems
- Clinical decision support (with proper oversight)
Legal Sector
- Document review
- Contract analysis
- Legal research assistance
- Drafting standard documents
Multilingual Applications
- Real-time translation
- Localization services
- Cross-language communication
Conclusion
Large Language Models (LLMs) represent a significant advancement in artificial intelligence, offering powerful capabilities for understanding and generating human-like text. Their transformer-based architecture, trained on vast datasets, enables them to perform a wide range of language tasks from content creation and customer support to coding assistance and data analysis.
However, LLMs are not perfect. They require careful implementation, human oversight, and ongoing refinement to ensure accuracy, reduce biases, and maintain ethical standards. While they excel at automating repetitive tasks and processing large volumes of text, they work best as tools to augment human expertise rather than replace it entirely.
As LLM technology continues to evolve, businesses and professionals should focus on:
- Responsible use (fact-checking outputs, avoiding misinformation)
- Task-specific fine-tuning (adapting models to industry needs)
- Balancing automation with human judgment (particularly for critical decisions)
When implemented thoughtfully, LLMs can improve efficiency, enhance creativity, and streamline workflows across industries. Their true value lies in how they complement human skills making complex tasks easier while leaving final decisions in the hands of professionals.
For more insights on AI and emerging technologies, visit capracode.com. Explore our library of articles and tutorials to stay informed about the latest developments.




